k8s(五)

组件
kubelet
kubelet 是运行在每个节点上的主要的"节点代理",每个节点都会启动 kubelet进程,用来处理 Master 节点下发到本节点的任务,按照 PodSpec 描述来管理Pod 和其中的容器(PodSpec 是用来描述一个 pod 的 YAML 或者 JSON 对象)。
kubelet 通过各种机制(主要通过 apiserver )获取一组 PodSpec 并保证在这些 PodSpec 中描述的容器健康运行。
kubelet 默认监听四个端口,分别为 10250 、10255、10248、4194。
LISTEN 0 128 *:10250 *:* users:(("kubelet",pid=48500,fd=28))
LISTEN 0 128 *:10255 *:* users:(("kubelet",pid=48500,fd=26))
LISTEN 0 128 *:4194 *:* users:(("kubelet",pid=48500,fd=13))
LISTEN 0 128 127.0.0.1:10248 *:* users:(("kubelet",pid=48500,fd=23))10250(kubelet API):kubelet server 与 apiserver 通信的端口,定期请求 apiserver 获取自己所应当处理的任务,通过该端口可以访问获取 node 资源以及状态。
10248(健康检查端口):通过访问该端口可以判断 kubelet 是否正常工作, 通过 kubelet 的启动参数 --healthz-port 和 --healthz-bind-address 来指定监听的地址和端口。
4194(cAdvisor 监听):kublet 通过该端口可以获取到该节点的环境信息以及 node 上运行的容器状态等内容,访问 http://localhost:4194 可以看到 cAdvisor 的管理界面,通过 kubelet 的启动参数 --cadvisor-port 可以指定启动的端口。
10255 (readonly API):提供了 pod 和 node 的信息,接口以只读形式暴露出去,访问该端口不需要认证和鉴权。
kubelet 主要功能:
- pod 管理:kubelet 定期从所监听的数据源获取节点上 pod/container 的期望状态(运行什么容器、运行的副本数量、网络或者存储如何配置等等),并调用对应的容器平台接口达到这个状态。
- 容器健康检查:kubelet 创建了容器之后还要查看容器是否正常运行,如果容器运行出错,就要根据 pod 设置的重启策略进行处理。
- 容器监控:kubelet 会监控所在节点的资源使用情况,并定时向 master 报告,资源使用数据都是通过 cAdvisor 获取的。知道整个集群所有节点的资源情况,对于 pod 的调度和正常运行至关重要。
kubelet 组件中的模块
1、PLEG(Pod Lifecycle Event Generator) PLEG 是 kubelet 的核心模块,PLEG 会一直调用 container runtime 获取本节点 containers/sandboxes 的信息,并与自身维护的 pods cache 信息进行对比,生成对应的 PodLifecycleEvent,然后输出到 eventChannel 中,通过 eventChannel 发送到 kubelet syncLoop 进行消费,然后由 kubelet syncPod 来触发 pod 同步处理过程,最终达到用户的期望状态。
2、cAdvisor cAdvisor(https://github.com/google/cadvisor)是 google 开发的容器监控工具,集成在 kubelet 中,起到收集本节点和容器的监控信息,大部分公司对容器的监控数据都是从 cAdvisor 中获取的 ,cAvisor 模块对外提供了 interface 接口,该接口也被 imageManager,OOMWatcher,containerManager 等所使用。
3、OOMWatcher 系统 OOM 的监听器,会与 cadvisor 模块之间建立 SystemOOM,通过 Watch方式从 cadvisor 那里收到的 OOM 信号,并产生相关事件。
4、probeManager probeManager 依赖于 statusManager,livenessManager,containerRefManager,会定时去监控 pod 中容器的健康状况,当前支持两种类型的探针:livenessProbe 和readinessProbe。 livenessProbe:用于判断容器是否存活,如果探测失败,kubelet 会 kill 掉该容器,并根据容器的重启策略做相应的处理。 readinessProbe:用于判断容器是否启动完成,将探测成功的容器加入到该 pod 所在 service 的 endpoints 中,反之则移除。readinessProbe 和 livenessProbe 有三种实现方式:http、tcp 以及 cmd。
5、statusManager statusManager 负责维护状态信息,并把 pod 状态更新到 apiserver,但是它并不负责监控 pod 状态的变化,而是提供对应的接口供其他组件调用,比如 probeManager。
6、containerRefManager 容器引用的管理,相对简单的Manager,用来报告容器的创建,失败等事件,通过定义 map 来实现了 containerID 与 v1.ObjectReferece 容器引用的映射。
7、evictionManager 当节点的内存、磁盘或 inode 等资源不足时,达到了配置的 evict 策略, node 会变为 pressure 状态,此时 kubelet 会按照 qosClass 顺序来驱赶 pod,以此来保证节点的稳定性。可以通过配置 kubelet 启动参数 --eviction-hard= 来决定 evict 的策略值。
8、imageGC imageGC 负责 node 节点的镜像回收,当本地的存放镜像的本地磁盘空间达到某阈值的时候,会触发镜像的回收,删除掉不被 pod 所使用的镜像,回收镜像的阈值可以通过 kubelet 的启动参数 --image-gc-high-threshold 和 --image-gc-low-threshold 来设置。
9、containerGC containerGC 负责清理 node 节点上已消亡的 container,具体的 GC 操作由runtime 来实现。
10、imageManager 调用 kubecontainer 提供的PullImage/GetImageRef/ListImages/RemoveImage/ImageStates 方法来保证pod 运行所需要的镜像。
11、volumeManager 负责 node 节点上 pod 所使用 volume 的管理,volume 与 pod 的生命周期关联,负责 pod 创建删除过程中 volume 的 mount/umount/attach/detach 流程,kubernetes 采用 volume Plugins 的方式,实现存储卷的挂载等操作,内置几十种存储插件。
12、containerManager 负责 node 节点上运行的容器的 cgroup 配置信息,kubelet 启动参数如果指定 --cgroups-per-qos 的时候,kubelet 会启动 goroutine 来周期性的更新 pod 的 cgroup 信息,维护其正确性,该参数默认为 true,实现了 pod 的Guaranteed/BestEffort/Burstable 三种级别的 Qos。
13、runtimeManager containerRuntime 负责 kubelet 与不同的 runtime 实现进行对接,实现对于底层 container 的操作,初始化之后得到的 runtime 实例将会被之前描述的组件所使用。可以通过 kubelet 的启动参数 --container-runtime 来定义是使用docker 还是 rkt,默认是 docker。
14、podManager podManager 提供了接口来存储和访问 pod 的信息,维持 static pod 和 mirror pods 的关系,podManager 会被statusManager/volumeManager/runtimeManager 所调用,podManager 的接口处理流程里面会调用 secretManager 以及 configMapManager。
Kustomize
Kustomize CLI 命令参考。
Kustomize 是一个用来定制 Kubernetes 配置的工具。它提供以下功能特性来管理应用配置文件:
- 从其他来源生成资源
- 为资源设置贯穿性(Cross-Cutting)字段
- 组织和定制资源集合
Kustomize 提供一个插件框架,允许用户开发自己的 生成器 和 转化器。
通过插件,实现 [generatorOptions] 和 [transformerconfigs] 无法满足的需求。
- generator 插件生成 k8s 资源,比如 helm chart inflator 是一个 generator 插件,基于少量自由变量生成一个 12-factor 应用所包含的全部组件 deployment,service,scaler,ingress 等)也是一个 generator 插件。
- transformer 插件转化(修改)k8s 资源,比如可能会执行对特殊容器命令行的编辑,或为其他内置转换器(
namePrefix、commonLabels等)无法转换的内容提供转换。
kubectl kustomize <kustomization_directory>ConfigMap 和 Secret 包含其他 Kubernetes 对象(如 Pod)所需要的配置或敏感数据。 ConfigMap 或 Secret 中数据的来源往往是集群外部,例如某个 .properties 文件或者 SSH 密钥文件。 Kustomize 提供 secretGenerator 和 configMapGenerator,可以基于文件或字面值来生成 Secret 和 ConfigMap
要基于文件来生成 ConfigMap,可以在 configMapGenerator 的 files 列表中添加表项。
ConfigMap 也可基于字面的键值偶对来生成。要基于键值偶对来生成 ConfigMap, 在 configMapGenerator 的 literals 列表中添加表项
Kustomize 支持组合不同的资源。kustomization.yaml 文件的 resources 字段定义配置中要包含的资源列表。 你可以将 resources 列表中的路径设置为资源配置文件的路径。
并非所有资源或者字段都支持策略性合并补丁。为了支持对任何资源的任何字段进行修改, Kustomize 提供通过 patchesJson6902 来应用 JSON 补丁的能力。 为了给 JSON 补丁找到正确的资源,需要在 kustomization.yaml 文件中指定资源的组(group)、 版本(version)、类别(kind)和名称(name)
Kustomize 中有 基准(bases) 和 覆盖(overlays) 的概念区分。 基准 是包含 kustomization.yaml 文件的一个目录,其中包含一组资源及其相关的定制。 基准可以是本地目录或者来自远程仓库的目录,只要其中存在 kustomization.yaml 文件即可。 覆盖 也是一个目录,其中包含将其他 kustomization 目录当做 bases 来引用的 kustomization.yaml 文件。 基准不了解覆盖的存在,且可被多个覆盖所使用。 覆盖则可以有多个基准,且可针对所有基准中的资源执行组织操作,还可以在其上执行定制
# 创建一个包含基准的目录
mkdir base
# 创建 base/deployment.yaml
cat <<EOF > base/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
run: my-nginx
replicas: 2
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
EOF
# 创建 base/service.yaml 文件
cat <<EOF > base/service.yaml
apiVersion: v1
kind: Service
metadata:
name: my-nginx
labels:
run: my-nginx
spec:
ports:
- port: 80
protocol: TCP
selector:
run: my-nginx
EOF
# 创建 base/kustomization.yaml
cat <<EOF > base/kustomization.yaml
resources:
- deployment.yaml
- service.yaml
EOFReplicaSet
ReplicaSet 的目的是维护一组在任何时候都处于运行状态的 Pod 副本的稳定集合。 因此,它通常用来保证给定数量的、完全相同的 Pod 的可用性。
在 kubernetes 环境中,通过 RelicaSet 这种资源对象就可以为我们实现集群的高可用。ReplicaSet (RS) 的主要作用就是为了维持一组 Pod 副本的运行,保证一定数量的 Pod 在集群正常运行,RelicaSet Controller 会持续监听它控制的这些 Pod 的运行状态,以及数量,保证应用集群高可用。例如:现在节点有 Pod 挂掉了,控制器会一直监视 Pod 的数量,发现少了一个 Pod,它会挑选一台合适的节点给我们拉起来,始终维持总数不变。不需要我们手动去处理,系统自己会为我们处理。
ReplicaSet 和 Deployment 联合起来控制无状态应用。ReplicaSet 并不是我们直接应该使用的控制器,虽然说它是一个非常重要的基础的控制器。而更加高级的抽象的也是我们使用最多的控制器叫 Deployment。借助一到多个 ReplicaSet 便捷的管理 Pod。从某种意义来讲,Deployment 是 ReplicaSet 控制器。Deployment 控制器在定义的时候却不定义与 Replicaset 有任何关系。定义的所有内容都是 Pod 模板。Pod 副本之类的。也就对用户而言,即便我们使用 Deployment 控制器,用户即便使用的是 ReplicaSet 控制器,用户对中间的 Replicaset 甚至无从感知的。 正确的管理方式是 Deployment->ReplicaSet->Pod。
ReplicaSet 控制器包含了 3 个基本的组成部分; 1.Selector: 标签选择器,匹配并关联 Pod 对象,并加入控制器的管理; 2.Replicas: 期望的副本数,期望在集群所运行的 Pod 的数量; 3.template:Pod 模板,其实就是 Pod 的规范,相当于把一个 Pod 的描述以模板嵌套进了 ReplicaSet
Deployment 控制器
Deployment (简写为 deploy) 是 kubernetes 控制器的又一种实现,构建于 ReplicasSet 控制器之上,可以为 Pod 和 ReplicaSet 提供声明式更新。相比较而言,Pod 和 ReplicaSet 很少用来直接使用,而是借助于控制器来使用。Deployment Controller 核心功能也是保证 Pod 资源的正常使用,大部分功能调用 ReplicaSet 来实现。
Deployment 控制器在 ReplicaSet 的基础上增加了部分特性:
- 事件和状态查看:可以通过特定的命令查看 Deployment 对象的更新进度和状态;
- 版本记录:将 Deployment 对象的历史更新操作都进行保存,以便于后续执行回滚操作使用;
- 多种更新方案: Recreate 重建,可以实现单批次更新所有的 Pod。RollingUpdate 可以实现多批次替换 Pod 至新版本。
Deployment 控制器详细信息中包含了其更新策略的相关配置。kubectl describe 命令中输出的 StrategyType、RollingUpdateStrategy 字段等
Deployment 控制器支持两种更新策略:滚动更新 (RollingUpdate) 和删除式更新 (Recreate) 也称为单批次更新。
- 删除式更新 (Recreate),当更新策略设定为 Recreate,在更新镜像时,它会先删除现在正在运行的 Pod,等彻底杀死后,重新创建新的 RS (ReplicaSet) 然后启动对应的 Pod,在整个更新过程中,会造成服务一段时间无法提供服务。也称之为单批次更新。
- 滚动更新 (Rolling Update) 滚动更新是默认的更新策略,一次仅更新一批 Pod,当更新的 Pod 就绪后再更新另一批,直到全部更新完成为止;该策略实现了不间断服务的目标,但是在更新过程中,不同客户端得到的响应内容可能会来自不同版本的应用。会出现新老版本共存状态。
Recreate 分为三个步骤:
- 杀死所有旧版本的 Pod,此时 Pod 无法正常对外提供服务;
- 创建新的 RS,启动新的 Pod;
- 等待 Pod 就绪,对外提供服务;
滚动更新(RollingUpdate)一次仅更新一批Pod,当更新的Pod就绪后,再更新另一批,直到全部更新完成为止,该策略实现了不间断服务的目标,在更新过程中可能会出现不同的应用版本且并存,同时提供服务的情况。
1.创建新的RS,然后根据新的镜像运行新的Pod。
2.删除旧的Pod,启动新的Pod,当新Pod就绪后,继续删除旧Pod,启动新Pod。
3.持续第二步过程,一直到所有Pod都被更新成功。
https://www.cnblogs.com/xunweidezui/p/16517663.html
ytt
配置yaml文件
安装
$ mkdir local-bin/
$ curl -L https://carvel.dev/install.sh | K14SIO_INSTALL_BIN_DIR=local-bin bash
$ export PATH=$PWD/local-bin/:$PATH
$ ytt versionyq
处理yaml文件
https://github.com/mikefarah/yq
https://mikefarah.gitbook.io/yq/
yq '.a.b[0].c' file.yamlk8s常见错误码
当容器终止时,容器引擎使用退出码来报告容器终止的原因。如果您是 Kubernetes 用户,容器故障是 pod 异常最常见的原因之一,了解容器退出码可以帮助您在排查时找到 pod 故障的根本原因。
0 正常退出 开发者用来表明容器是正常退出
1 应用错误 容器因应用程序错误或镜像规范中的错误引用而停止
125 容器未能运行 docker run 命令没有执行成功
126 命令调用错误 无法调用镜像中指定的命令
127 找不到文件或目录 找不到镜像中指定的文件或目录
128 退出时使用的参数无效 退出是用无效的退出码触发的(有效代码是 0-255 之间的整数)
134 异常终止 (SIGABRT) 容器使用 abort () 函数自行中止
137 立即终止 (SIGKILL) 容器被操作系统通过 SIGKILL 信号终止
139 分段错误 (SIGSEGV) 容器试图访问未分配给它的内存并被终止
143 优雅终止 (SIGTERM) 容器收到即将终止的警告,然后终止
255 退出状态超出范围 容器退出,返回可接受范围之外的退出代码,表示错误原因未知
Pod 处于 CrashLoopBackOff 状态
容器进程主动退出
系统 OOM
cgroup OOM
节点内存碎片化
健康检查失败
证书管理
在我们谈到 Kubernetes 证书时,我们指的是数字证书 Digital Certificate ,也就是基于 X.509 V3 标准的证书。
它通过将身份与一对可用于对数字信息进行加密、签名和解密的电子密钥绑定,以实现认证和数据安全(一致性、保密性)的保障。
每一个 X.509 证书都是根据公钥和私钥组成的密钥对来构建的,它们能够用于加解密、身份验证、信息安全性确认。
X.509 标准使用了一种抽象语法表示法 One (ASN.1) 的接口描述语言,来定义、和编解码客户端与证书颁发机构之间传输的证书请求和证书。
公钥和私钥都是由一长串随机数组成的。公钥是公开的,由长度来决定保护强度,但是信息会通过公钥来加密。私钥只在接受者处秘密存储,接受者通过使用公钥关联的私钥才能解密读取信息。
用于生成公钥的最常见加密算法有以下三种:
- Rivest–Shamir–Adleman (RSA) :RSA 来自 Ron Rivest、Adi Shamir 和 Leonard Adleman 这三个人的姓氏,他们于 1977 年公开描述了 “ RSA” 算法。RSA 根据两个大质数和一个辅助值创建并发布公钥。质数是保密的。消息可以由任何人通过公钥加密,但只能由知道素数的人解码。
- 椭圆曲线密码学 (ECC):Elliptic Curve Cryptography,是一种基于椭圆曲线数学的公开密钥加密算法。它可以在保障跟 RSA 同等的安全级别下,使用的字符串长度更小。它还可以基于 Weil pairing 或者 Tate pairing 定义群之间的双线性映射。
- 数字签名算法 (DSA) :1991 年由美国国家标准技术研究所(NIST)提出,有专利,并且 NIST 在实行买断式授权。
证书内容的编码(即,文件中存储的内容编码)在 X.509 标准中还没有被界定下来。
目前常见编码模式有两种:
- 可分辨编码规则 (DER):二进制格式,最常见,因为 DER 能处理大部分数据。DER 编码的证书是二进制文件,文本编辑器无法直接读取。聊到这里,你可能会好奇,那么为什么叫它 “可分辨编码” 呢?这是由于它的编码方式都是公开的,就比如前面我给出的示例中,有个
SEQUENCE,它通过 DER 编码的时候标记编号是0x30,这样就可以很容易分辨出来了; - 隐私增强邮件 (PEM):ASCII 文本格式,这是一种加密的电子邮件编码规则,可将 DER 编码的证书转换为文本文件。用 OpenSSL 工具的话,很简单
openssl x509 -in <filename>.cer -inform DER -out <filename>.pem -outform PEM就可以了。
证书的颁发和信任链
Certification Authority 简称 CA,它是证书的认证权威机构。它的体系是一个树形结构,每一个 CA 可以有一到多个子 CA ,顶层 CA 被称为根 CA 。除了根 CA 以外,其他的 CA 证书的颁发者是它的上一级 CA 。这种层级关系组成了信任链(Trust Chain)。
以一个实际的例子来看,比如通过 cloudflare 提供了 SSL 证书,那么查看证书的时候,就可以看到它的根是 Baltimore CyberTrust Root,中间证书是 Cloudflare Inc ECC CA-3,最后则是 `sni.cloudflaressl.com`
证书分为两种类型(没有本质区别):
- CA 证书(CA Certificate)
- 终端实体证书(End Entity Certificate) 接受 CA 证书的最终实体。
X.509 标准还定义了证书吊销列表(Certificate revocation list ,CRL)的使用。CRL 是尚未到期就被证书颁发机构 CA 吊销的证书的名单。在 CRL 中的证书就不会受到信任了。
根据在 RFC 3280 中的定义,吊销有两种不同的状态:
- 吊销:不可逆。被吊销的最常见的原因是私钥泄露。
- 吊扣:是可逆的。
客户端应验证服务器提供的证书或用作 CA 的证书的序列号未出现在 CRL 中。理想情况下,每次验证证书时,都会根据当前版本的域 CRL 检查这些序列号。实际上,每个连接都拉取一遍更新的 CRL 会给流程增加很多开销。所以大多数客户端会使用缓存,缓存虽然不能保证是最新的,但可以避免在托管 CRL 的站点不可用时出现问题。
Public Key Infrastructure,简称 PKI,是公钥基础结构。PKI 的核心是在客户端、服务器和证书颁发机构 (CA) 之间建立的信任。这种信任是通过证书的生成、交换和验证来建立和传播的。
K8S 基于 CA 签名的双向数字证书
在 Kubernetes 中,各个组件提供的接口中包含了集群的内部信息。出于对集群安全的考虑,需要组件之间的通信需要采用双向 TLS 认证,以防出现接口被非法访问的情况。(即客户端和服务器端都需要验证对方的身份信息)。就是 A 向 B 发出信息前,需要确认 B 是个真的 B;而 B 对 A 作出响应,也需要确认 A 是真的 A 。
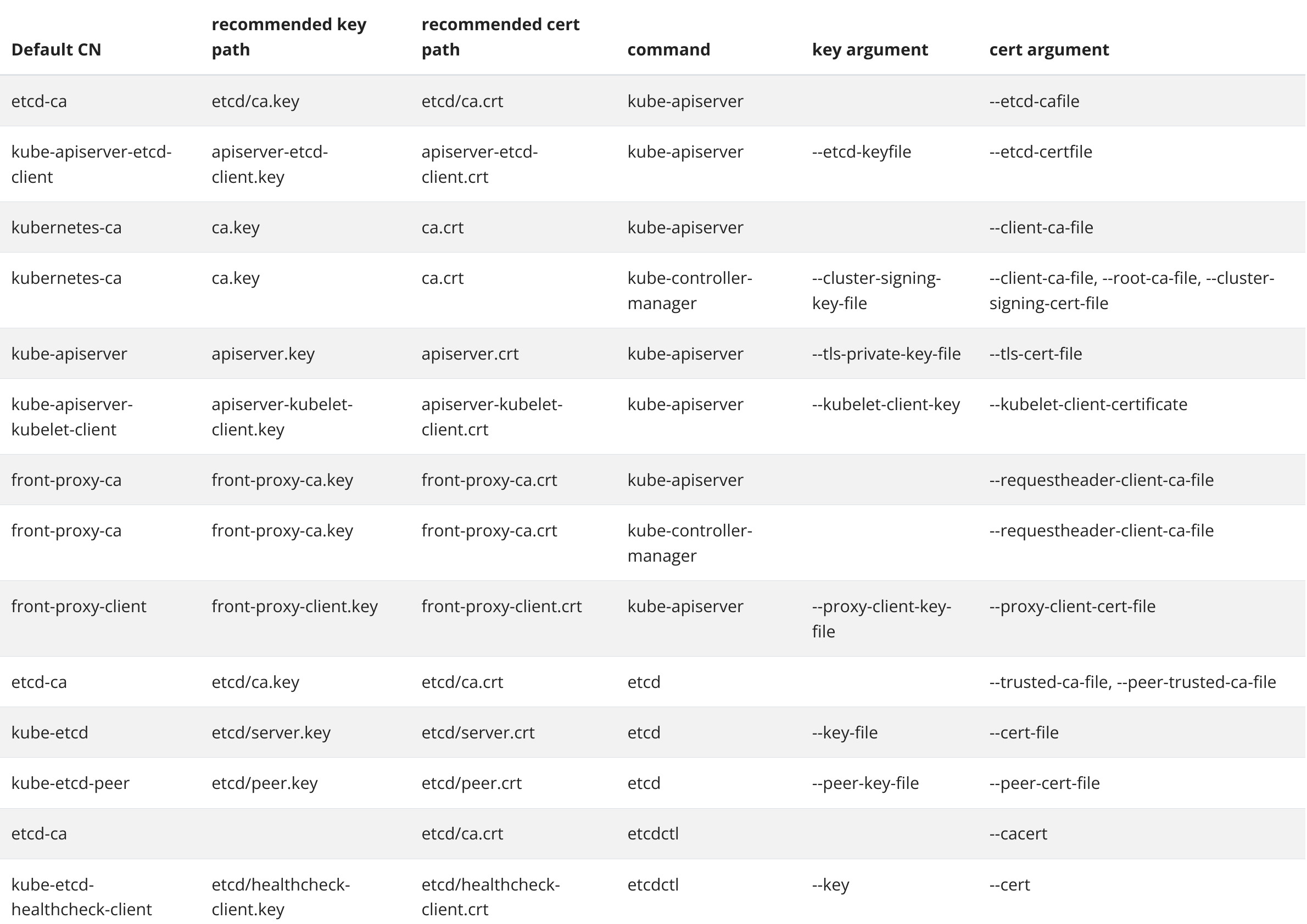
K8S 集群中的证书主要包含如下部分:
- Kubelet 客户端证书,用于 API 服务器身份验证
- Kubelet 服务端证书, 用于 API 服务器与 Kubelet 的会话
- API 服务器端证书
- 集群管理员的客户端证书,用于 API 服务器身份认证
- API 服务器的客户端证书,用于和 Kubelet 的会话,还有和 etcd 的会话
- kube-controller-manager 的客户端证书,用于和 API 服务器的会话
- kube-scheduler 的客户端证书或 kubeconfig,用于和 API 服务器的会话
- 前端代理的客户端及服务端证书
- etcd 相关,用于客户端和其他对等节点进行身份验证。
通过 kubeadm 安装 Kubernetes,大多数证书都存储在 /etc/kubernetes/pki。 本文档中的所有路径都是相对于该目录的,但用户账户证书除外,kubeadm 将其放在 /etc/kubernetes 中
在一个 K8S 集群中,可以存在多个以独立进程形式存在的组件。这些组件通过相互通信来实现,集群的运行、管理等工作。上文也已解释过,对于各个需要通信的组件来讲,关键的是需要验证通信双方的身份是否符合预期,以免受到安全威胁
在两个组件需要进行双向认证时,就涉及到了一系列证书(参照上一部分罗列的证书文件)。
对于这些证书的管理涉及到了从生成、分发、续签等等实际生产中需要用到的方方面面
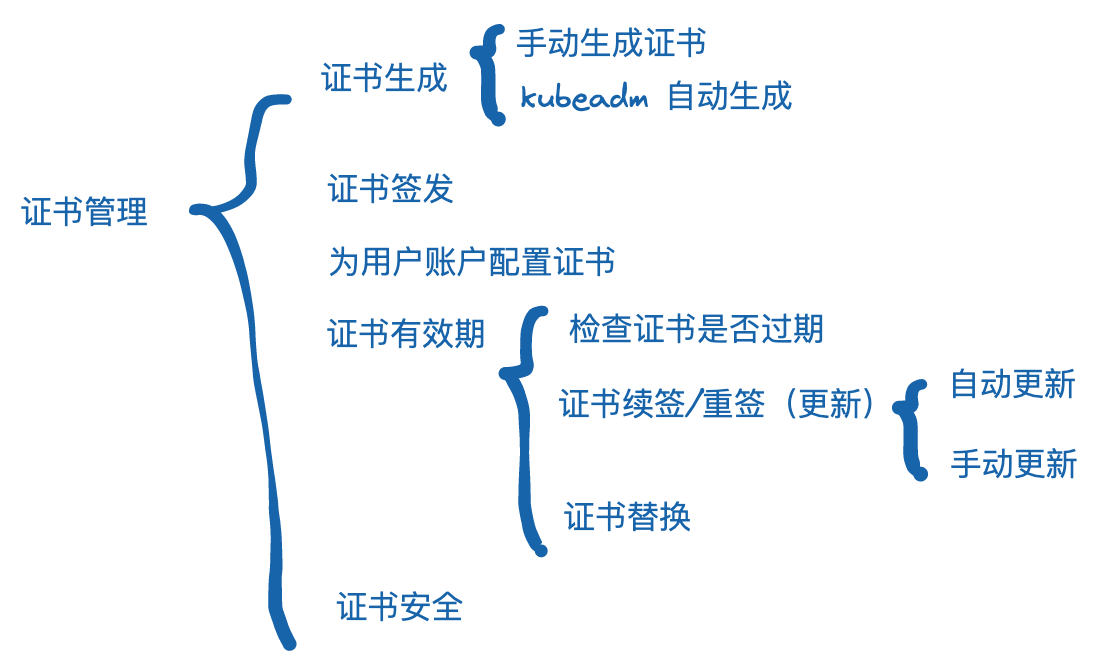
相关命令
综上,K8S 的证书管理过程中,我们需要面对一些问题:
- 证书种类繁多
- 证书数量繁多
- 证书管理命令行工具参数繁多,存在一定的使用复杂度
- 管理过程及检验过程不直观
- 人为操作风险较高
至此,一些 Kubernetes 中的证书管理器的项目应运而生。
cert-manager
cert-manager几乎已经成为了 Kubernetes 中证书管理领域的事实标准了。
从 2016 年至今,证书管理器经历了支持 + 扩展的历程。如今,我们可以很便捷的使用 cert-manager 来实现 Kubernetes 集群中的证书管理工作啦。
cert-manager 所管理的证书,主要是为部署在 Kubernetes 中的服务所使用的,而非给 Kubernetes 自身。通常我们可以使用 kubeadm certs 命令来完成大多数通过 kubeadm 部署的 Kubernetes 集群的证书相关操作。
cert-manager 将证书和证书颁发者作为自定义资源类型添加到 Kubernetes 集群中,并简化了这些证书的获取、更新和使用过程
cert-manager 可以从各种受支持的来源颁发证书,包括 Let's Encrypt、HashiCorp Vault 和 Venafi 以及私有 PKI。
- Let's Encrypt 是全球证书颁发机构 (CA),可以获取、更新和管理 SSL/TLS 证书。网站可以使用 Let's Encrypt 的证书来启用安全的 HTTPS 连接。Let's Encrypt 是一个非营利组织,对于大多数浏览器和操作系统都信任来自 Let's Encrypt 的证书。在不停机的情况下自动 / 手动颁发和安装证书的话,需要借助 Certbot (一款免费的开源软件工具)来启用 HTTPS。
- HashiCorp Vault 是一个开源的密钥和隐私数据管理工具。它提供了非常丰富的功能,除了常规的密钥存储外,还支持证书签发,策略管理等能力。
- Venafi 机器身份管理平台。
与Ingress集成
cert-manager 中的一个组件 ingress-shim 负责通过向 Ingress 资源添加注释来实现请求 TLS 签名证书来保护 Ingress 资源。ingress-shim 会监控集群中的 Ingress 资源,如果 Ingress 的 annotation 中出现了 cert-manager 所支持的部分,则会对应的创建证书资源。
与GateWay API集成
Gateway API 是由 Kubernetes 社区的 SIG-Network 管理的开源项目,是一组安装在 Kubernetes 集群上的 CRD。主要目标是替换 Ingress,号称下一代 Ingress 。
GateWay API 有三种主要类型的对象:
- GatewayClass 定义一组具有通用配置和行为的网关。它是集群范围的资源。通常由基础设施供应商进行操作和管理。
- Gateway 定义了如何将流量转发到集群内服务。
-
Routes 将来自 Gateway 的流量映射到服务。它定义了将请求从网关映射到 Kubernetes 服务的规则。从 v1alpha2 开始,API 包含四种 Route 资源类型:
- [7 层] HTTPRoute :用于多路复用 HTTP 或进行 HTTPS 卸载。即对使用 HTTP 请求的数据进行路由或修改。
- [4-7 层间] TLSRoute :用于多路复用 TLS 连接,通过 SNI 进行区分。
- [4 层] TCPRoute(和 UDPRoute):将一个或多个端口映射到单个后端。
- [7 层] GRPCRoute :用于路由 gRPC 流量。
与Istio集成
istio-csr 是一个 agent,允许使用 cert-manager 保护 Istio workload 和控制平面组件 。istio-csr 实现了 gRPC Istio 证书服务,该服务对来自 Istio workload 的传入证书签名请求进行身份验证、授权和签名,并通过安装在集群中的 cert-manager 路由所有证书的处理。
K8s健康检查
k8s健康检测主要分为以下三种
存活性探测(Liveness probes) :主要是探测应用是否还活着。如果检测到应用没有存活就杀掉当前pod并重启。
就绪性探测(Readiness probes):只要是探测应用是否准备好接受请求访问,如果检测应用准备好了,就把请求流量放进来;反之,则把应用节点从注册中心拿掉。
启动探测(Startup Probes):对于旧应用需要更长的启动时间,这时候既不想重启应用也不想让请求访问进来,可以设置启动探测给足够的启动时间保证应用启动成功。
initialDelaySeconds 表示延迟30S开始第一次探测,默认值是0,最小值是0
timeoutSeconds 表示每次探测的超时时间,35S后如果没返回结果就认为超时失败,默认值是1,最小值是1
successThreshold 表示在探测失败后,最小的连续成功被认为是成功的,默认值是1,最小值是1
failureThreshold 表示当探测失败时,Kubernetes将在认为失败前尝试failureThreshold次数。默认值是3,最小值是1;Liveness认为失败的操作是重启pod,而readiness认为失败的操作是把pod标记为 Unready
periodSeconds 表示多久进行一次探测,默认是10S,最小值是1成功:容器通过了探测
失败:容器未通过探测
未知:容器探测失败,不采取任何操作velero
https://github.com/vmware-tanzu/velero
备份和迁移持久卷
配置管理configMap和secret
k8s中的secret和configmap是为了让POD和配置解耦,使得从集群外部可以想容器内部注入配置信息、环境变量等功能
ConfigMap扮演了K8S集群中配置中心的角色,ConfigMap定义了Pod的配置信息,可以以存储卷的形式挂载至Pod中的应用程序配置文件目录,从ConfigMap中读取配置信息
ConfigMap是明文保存的,如果用来保存数据库账号密码这类信息可以使用通过secret来保存,secret的功能和ConfigMap一样,不过secret是通过Base64的编码机制保存配置信息 可以通过命令行的方式来创建configmap,
kubectl create configmap nginx-config --from-literal=nginx_server_port=8080 --from-literal=nginx_server_name=www.sulao.cn
configmap/my-config created亦可以通过调用配置文件的方式来创建configmap,yaml文件内容如下
vi vhost.conf
server {
listen 8080;
server_name www.sulao.cn;
root /data/www;
}
kubectl create configmap nginx-config --from-file=./vhost.conf
vi nginx-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
spec:
containers:
- name: nginx
image: nginx
volumeMounts : #定义容器使用存储卷挂载
- name: config #使用存储卷的名称
mountPath: /etc/nginx/conf.d/
volumes:
- name: config #存储卷名称
configMap: #存储卷类型:这里为configmap而不是nfs其他的文件系统,可以指定configmap资源为存储卷
name: nginx-config #configmap名称,这里为我们刚才创建的cm名称
items : #使用cm中的key
- key: vhost.conf #key名称
path: sulao.cn.conf #表示映射为文件时文件名是什么--from-file=./vhost.conf #利用文件来传递参数,没有给key名称默认为文件名称为key,这里所以文件名就是vhost.conf,文件内容为vhost.conf文件内的内容,当然也可以指定文件名,那么我们创建configmap是需要这样命名
Secret 对象类型用来保存敏感信息,例如密码、OAuth 令牌和 SSH 密钥。 将这些信息放在 secret 中比放在 Pod 的定义或者 容器镜像中来说更加安全和灵活。
Secret 是一种包含少量敏感信息例如密码、令牌或密钥的对象。 这样的信息可能会被放在 Pod 规约中或者镜像中。 用户可以创建 Secret,同时系统也创建了一些 Secret。
要使用 Secret,Pod 需要引用 Secret。 Pod 可以用三种方式之一来使用 Secret:
- 作为挂载到一个或多个容器上的卷中的文件。
- 作为容器的环境变量
- 由 kubelet 在为 Pod 拉取镜像时使用
Kubernetes 提供若干种内置的类型,用于一些常见的使用场景。 针对这些类型,Kubernetes 所执行的合法性检查操作以及对其所实施的限制各不相同。
| 内置类型 | 用法 |
|---|---|
| Opaque | 用户定义的任意数据 |
| kubernetes.io/service-account-token | 服务账号令牌 |
| kubernetes.io/dockercfg | ~/.dockercfg 文件的序列化形式 |
| kubernetes.io/dockerconfigjson | ~/.docker/config.json 文件的序列化形式 |
| kubernetes.io/basic-auth | 用于基本身份认证的凭据 |
| kubernetes.io/ssh-auth | 用于 SSH 身份认证的凭据 |
| kubernetes.io/tls | 用于 TLS 客户端或者服务器端的数据 |
| bootstrap.kubernetes.io/token | 启动引导令牌数据 |
Kubernetes 对于 Secret 和 ConfigMap 提供了一种不可变更的配置选择,对于大量使用 Secret 的集群(至少有成千上万各不相同的 Secret 供 Pod 挂载), 禁止变更它们的数据有下列好处:
- 防止意外(或非预期的)更新导致应用程序中断
- 通过将 Secret 标记为不可变来关闭 kube-apiserver 对其的监视,从而显著降低 kube-apiserver 的负载,提升集群性能。
将 Secret 的 immutable 字段设置为 true 创建不可更改的 Secret
apiVersion: v1
kind: Secret
metadata:
...
data:
...
immutable: true1、当一个 secret 设置成不可更改,如果想要更改 secret 中的内容,就需要删除并且重新创建这个 secret
2、对于引用老的 secret 的 pod,需要删除并且重新创建
Secret 与 ConfigMap 对比
相同点:
- key/value 的形式
- 属于某个特定的 namespace
- 可以导出到环境变量
- 可以通过目录 / 文件形式挂载 (支持挂载所有 key 和部分 key)
不同点:
- Secret 可以被 ServerAccount 关联 (使用)
- Secret 可以存储 register 的鉴权信息,用在 ImagePullSecret 参数中,用于拉取私有仓库的镜像
- Secret 支持 Base64 加密
- Secret 文件存储在 tmpfs 文件系统中,Pod 删除后 Secret 文件也会对应的删除。
https://boilingfrog.github.io/2021/06/27/k8s%E4%B8%AD%E7%9A%84Secret%E7%90%86%E8%A7%A3/
快速部署k8s
kubernetes-vagrant-centos-cluster
repo:https://github.com/rootsongjc/kubernetes-vagrant-centos-cluster
部署文档:https://github.com/rootsongjc/kubernetes-vagrant-centos-cluster/blob/master/README-cn.md
skaffold
https://skaffold.dev/docs/install/
https://rainfd.com/post/17_skaffold%E7%AE%80%E6%98%93%E6%95%99%E7%A8%8B/
官方支持 Build 的方式有:
- Docker, 最常见的
- Bazel,Google 内部开源的构建系统,用得不多
- Custom,自定义镜像来执行任意命令来完成构建
- Jib,Java 专用
- ko,go 专用
简单来说就是一个本地的 CICD 工具,可以将你的应用快速部署到 Kubernetes 集群。
我们当前用的 CI 是 Jenkins 或者 GitLab CI,部署使用 helm,使用的过程中会遇到几个问题:
- CICD 即便用上了之前定义好的模板,实际用起来总有需要修改的地方。无论是 Jenkins 还是 GiLab ,都没有提供很好的本地调试工具,调试的过程又慢又痛苦
- 应用测试的时候很多情况下是无法单靠服务的响应和日志来定位问题,这个时候要不就是用本地开发环境的服务来复现问题,要不就是将本地的服务接入测试环境来 debug 问题,整个环境切换的流程非常麻烦
而 Skaffold 正好切中了这些问题:
- 简化 CICD 流程 由于 Skaffold 可以直接在本地运行,再加上配置简单,所以整个流程可以很方便地进行调试。而且一旦配置完毕,其他人就能直接使用命令进行操作。
- 加速 CICD 流程 Skaffold 有命令
skaffold run,从代码构建到部署到 Kuberenetes 集群上,执行的整个流程最快只需要几秒。而原来必须先推送代码,等 Jenkins 检测到变更在慢吞吞地起任务构建。这个旧的流程至少也得花上一两分钟,多的甚至要五六分钟。 - 更方便地部署调试 Skaffold 在 VSCode 和 GoLand 都有对应的插件,提供了远程调试的功能,实现了跟本地调试基本一样的体验。
与 Skaffold 方案类似的有 tilt、DevSpace,okteto 和 Nocalhost。